
Can artificial intelligence help us understand the mysteries of our DNA?
Last year (2024), the Nobel Prize in Chemistry was awarded to the development of a computer program that uses AI to predict the three-dimensional structure of protein molecules based only on the amino acid sequence of the protein written in genetic DNA. Knowing the three-dimensional structure of a protein is the most important thing for understanding how the protein works and developing drugs, and each three-dimensional structure is completely different depending on the amino acid sequence. The amino acid sequence is built into the structure of DNA, but despite long research, the relationship between the amino acid sequence and the three-dimensional structure was not understood. Google’s AI research group has succeeded in predicting the three-dimensional structure from the amino acid sequence (DNA) for the first time (see this website’s latest news, December 28, 2024). Last month, another research group at the same Google company announced that they had created a program to analyze the structure of the part of DNA excluding the part that specifies the amino acid sequence. The media has reported that this newly developed program may be used to design the information instruction manual of new life.
Now, let us briefly introduce what the newly elucidated DNA structure is and what can be done based on it. If you read the actual paper (preprint before publication in a scientific journal, Zeiga Avsec et al., Alpha genome: advancing regulatory variant effect prediction, (2025) Google), it is quite difficult to understand. Therefore, I would like to briefly introduce some clues to understanding the contents of this paper.
The fundamental information necessary for us humans to live as living organisms is contained in our parents’ DNA, and we inherit information by replicating our parents’ DNA. That is why children resemble their parents. DNA has a thread-like (or chain-like) structure made up of 3 billion basic unit substances called nucleotides. This thread (chain) of DNA is received half each from our father’s sperm and our mother’s egg, and forms a set in the fertilized egg, which is contained in the nucleus of almost all cells (60 trillion) that have multiplied. To create each protein from this DNA, a molecule called RNA on the thread is replicated (called transcription), and the RNA moves to the ribosomes in the cell, where amino acids are linked based on the amino acid sequence information of the RNA to create proteins (called translation).
There are two major problems that remain unsolved. The first problem is that while about 10% of DNA is used to specify the arrangement of amino acids, the role of the remaining 90% is still unclear. The other problem is that we are made up of 60 trillion cells, each of which has its own unique protein and performs a different function. For example, the cells of the retina of the eye contain an essential protein called rhodopsin that receives light from outside. The protein part of rhodopsin called opsin is produced in large quantities in the retina, but opsin is not produced in nerve cells of the brain, and proteins necessary for other nerve functions are produced instead. Also, the speed at which newborn children and adults grow taller is different, but this is due to the difference in the speed at which proteins are produced based on DNA. In this way, the information written in DNA is read as different proteins according to the needs of the cell, and the speed at which they are produced is also different. How on earth is this regulated?
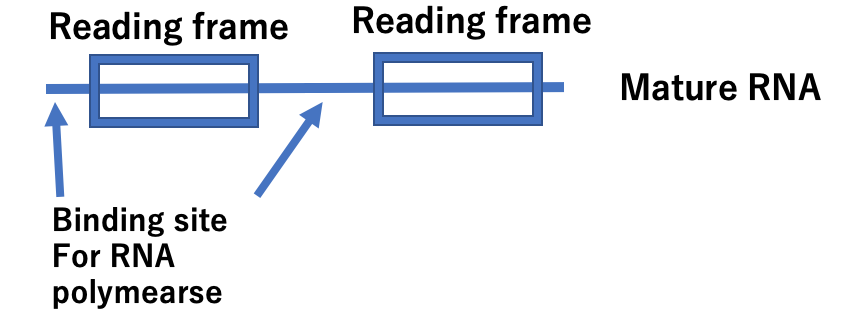
mRNA, which is a copy of the information in DNA, is produced by enzymes based on DNA. This enzyme (RNA polymerase) requires a special nucleotide sequence in DNA to bind to DNA. Synthesis of the copy sequence begins only when another protein that regulates the binding, other than the polymerase, binds to this sequence. In this way, it is important to note that the regulation of the creation of copy RNA involves a special DNA sequence and the protein that binds to it. In addition, this regulation is also deeply related to the order in which proteins are created over time since the birth of the cell. The DNA structure involved in this regulation of RNA synthesis is located outside the part that specifies the amino acid sequence. Most of it is located in the 90% of the DNA mentioned at the beginning. The mechanism of gene transcription regulation in this part is not yet fully understood. What is particularly important is that RNA, which is a copy of DNA, can be produced from this part, and this RNA is not used to synthesize proteins, but rather binds to mRNA that commands the sequence of another protein and is used to suppress its synthesis.
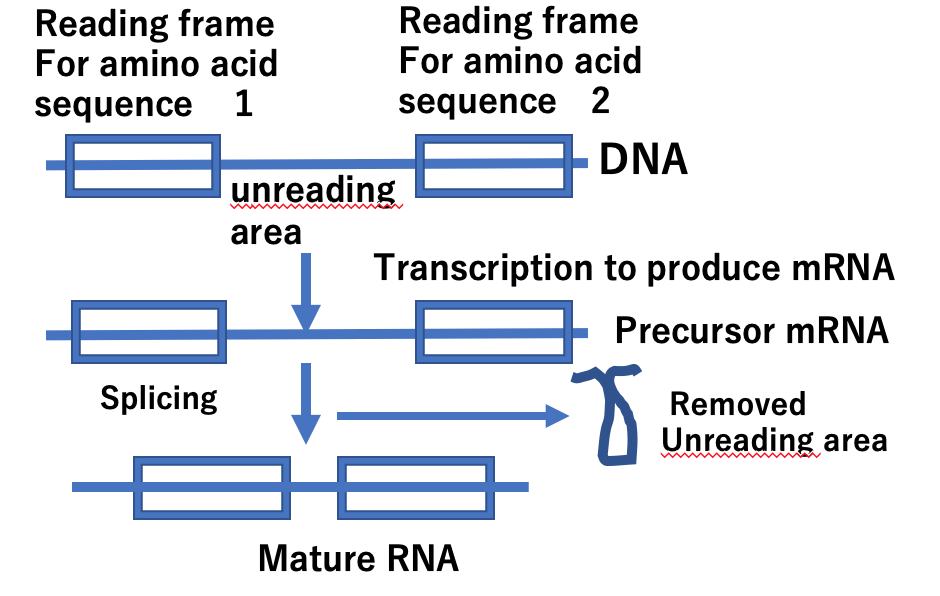
There is another special mechanism for regulation at the stage of creating DNA copy RNA. This is a mechanism called splicing. In human cells, RNA, which is a replicated copy of DNA, is not the final length immediately after synthesis, but a precursor RNA (precursor RNA) with a longer total length is produced. Furthermore, this long precursor RNA is joined at distant positions within the RNA, and the protruding parts are pinched off. This is called splicing. There is a rule for the joining of distant RNA parts that are pinched off, and this information is inherent in the nucleotide sequence of DNA. It is estimated that the number of types of proteins that are actually produced is greater than the number of types of proteins currently known in cells, and this is because multiple proteins are produced from one gene by splicing. The total number is not yet clear. To elucidate this, it is necessary to identify the nucleotide sequence involved in new splicing in the structure of DNA. It is also known that proteins that bind to the pinched off parts are involved in splicing.
So far, we have mentioned that it is important for special proteins to bind to special structures of DNA in the regulation of the creation of DNA copy molecules (transcription regulation, splicing regulation, etc.). To analyze such sequences, it is first necessary to memorize all 3 billion base sequences in humans, compare the subtle differences in DNA sequences from cell to cell, and compare the changes in DNA sequences when cells become cancerous. This is something that cannot be done by the human brain, and is impossible without the aid of a computer.
In the recently published paper titled Alpha Genome, the DNA of two types of cultured human cells was memorized by a supercomputer, and the state of the cells that occurs when these cells are artificially altered, as well as information recording the DNA changes and disease symptoms, were also memorized by the computer.
If a researcher determines even a portion of the DNA sequence of a cell in hand, such as a cancer cell, inputs it into this program and analyzes it with Alpha Genome, it is possible to determine the characteristics necessary for the expression of the genes in this cell and predict the disease condition without conducting molecular biology experiments. Furthermore, if the gene expression is as predicted by the program when cells in hand are analyzed, the validity of the program and even the discovery of the program will be a new molecular biology discovery. By combining these things, it may be possible to design the DNA necessary to create cells that function completely artificially.